MNIST 분류 튜토리얼
MNIST 손글씨 숫자 분류 모델을 처음부터 끝까지 학습하는 완전한 튜토리얼입니다. 런타임에 데이터셋을 다운로드하는 방식으로 별도의 데이터셋 업로드 없이 학습할 수 있습니다.
이 튜토리얼을 진행하기 전에:
- keynet-train 0.8.5 이상 설치 (0.7.4 이상 호환)
- Docker가 설치되어 있고 실행 중이어야 합니다
- KeyNet platform 계정이 있어야 합니다
학습 Workflow
- 파란색 박스: 로컬 환경에서 수행하는 작업
- 주황색 박스: KeyNet Platform에서 수행하는 작업
1. Platform에서 프로젝트 생성
KeyNet platform에 로그인한 후 프로젝트를 생성합니다.
이전 버전과 달리, 이제 모델을 수동으로 생성할 필요가 없습니다. keynet-train push 명령어가 자동으로 모델을 생성합니다.
2. 학습 코드 작성
프로젝트 구조
mkdir mnist-tutorial
cd mnist-tutorial
필요한 파일:
mnist-tutorial/
├── train.py # 학습 스크립트
└── requirements.txt # Python 의존성
requirements.txt
keynet-train==0.8.5
train.py
Docker로 첫 학습 실행에서 사용한 코드를 그대로 사용합니다:
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import mlflow
from keynet_train import trace_pytorch
# 간단한 CNN 모델 정의
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, 2)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return torch.log_softmax(x, dim=1)
def train_epoch(model, device, train_loader, optimizer, epoch):
"""한 epoch 학습"""
model.train()
total_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
# 통계 수집
total_loss += loss.item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += len(data)
avg_loss = total_loss / len(train_loader)
accuracy = 100.0 * correct / total
return avg_loss, accuracy
def validate(model, device, test_loader):
"""Validation 수행"""
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += nn.functional.nll_loss(output, target, reduction="sum").item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100.0 * correct / len(test_loader.dataset)
return test_loss, accuracy
# @trace_pytorch 데코레이터로 자동화된 학습 함수
@trace_pytorch(
model_name="mnist-classification",
sample_input=torch.randn(1, 1, 28, 28),
base_image="pytorch/pytorch:2.8.0-cuda12.9-cudnn9-runtime"
)
def train_mnist(batch_size, epochs, learning_rate):
# Device 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# Dataset 준비 (런타임 다운로드)
data_dir = "./data" # MNIST 데이터셋 저장 경로
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
train_dataset = datasets.MNIST(
data_dir, train=True, download=True, transform=transform
)
test_dataset = datasets.MNIST(data_dir, train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# Model 초기화
model = SimpleCNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Hyperparameters logging
mlflow.log_params({
"batch_size": batch_size,
"epochs": epochs,
"learning_rate": learning_rate,
"optimizer": "Adam",
"device": str(device),
})
print("🚀 학습 시작...")
# 학습 loop
for epoch in range(1, epochs + 1):
# Training
train_loss, train_acc = train_epoch(
model, device, train_loader, optimizer, epoch
)
# Validation
val_loss, val_acc = validate(model, device, test_loader)
# Metric logging
mlflow.log_metrics({
"train_loss": train_loss,
"train_accuracy": train_acc,
"val_loss": val_loss,
"val_accuracy": val_acc,
}, step=epoch)
print(
f"Epoch {epoch}/{epochs}: "
f"Train Loss={train_loss:.4f}, Train Acc={train_acc:.2f}% | "
f"Val Loss={val_loss:.4f}, Val Acc={val_acc:.2f}%"
)
# 최종 결과
print(f"✅ 학습 완료! 최종 Validation Accuracy: {val_acc:.2f}%")
return model
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="MNIST Classification Training")
parser.add_argument("--batch-size", type=int, default=64, help="Training batch size (default: 64)")
parser.add_argument("--epochs", type=int, default=5, help="Number of training epochs (default: 5)")
parser.add_argument("--learning-rate", type=float, default=0.001, help="Learning rate (default: 0.001)")
args = parser.parse_args()
train_mnist(
batch_size=args.batch_size,
epochs=args.epochs,
learning_rate=args.learning_rate,
)
핵심 포인트:
datasets.MNIST는 런타임에 데이터를 자동 다운로드합니다 (download=True)- Platform에서 별도의 데이터셋 업로드가 필요 없습니다
@trace_pytorch데코레이터에model_name과base_image를 지정해야 합니다
3. CLI 인증 및 이미지 업로드
keynet-train CLI를 사용하여 Platform 인증 및 이미지 빌드/업로드를 한 번에 처리합니다.
Platform 로그인
keynet login https://gateway.aiplatform.re.kr
입력 프롬프트:
Username: YOUR@EMAIL
Password: ********
Login Succeeded
✅ Logged in to https://gateway.aiplatform.re.kr
✅ Docker login successful
Email: YOUR@EMAIL
Password:
✓ Platform authentication successful
✓ Harbor login successful
✓ Configuration saved
╭────────────────── Login Complete ───────────────────╮
│ │
│ Server: https://gateway.aiplatform.re.kr │
│ User: YOUR@EMAIL │
│ Expires: 2025-12-10T10:53:23.619082Z │
│ Config: /Users/hbjs/.config/keynet/config.json │
│ │
╰─────────────────────────────────────────────────────╯
이미지 빌드 및 업로드
keynet-train push train.py
CLI가 자동으로 다음 작업을 수행합니다:
@trace_pytorch데코레이터에서model_name과base_image추출- Dockerfile 자동 생성
- Docker 이미지 빌드
- Platform에 모델 생성 (자동)
- Harbor에 이미지 push
자동 생성되는 Dockerfile:
FROM pytorch/pytorch:2.8.0-cuda12.9-cudnn9-runtime
WORKDIR /workspace
COPY . /workspace/
RUN if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
CMD ["python", "train.py"]
4. Empty Dataset 생성
MNIST는 런타임에 데이터를 다운로드하므로 실제 데이터셋 업로드가 필요 없습니다.
"데이터셋 생성" 버튼을 클릭하고, 이름을 입력한 후 파일을 선택하지 않고 "생성" 버튼을 클릭합니다.
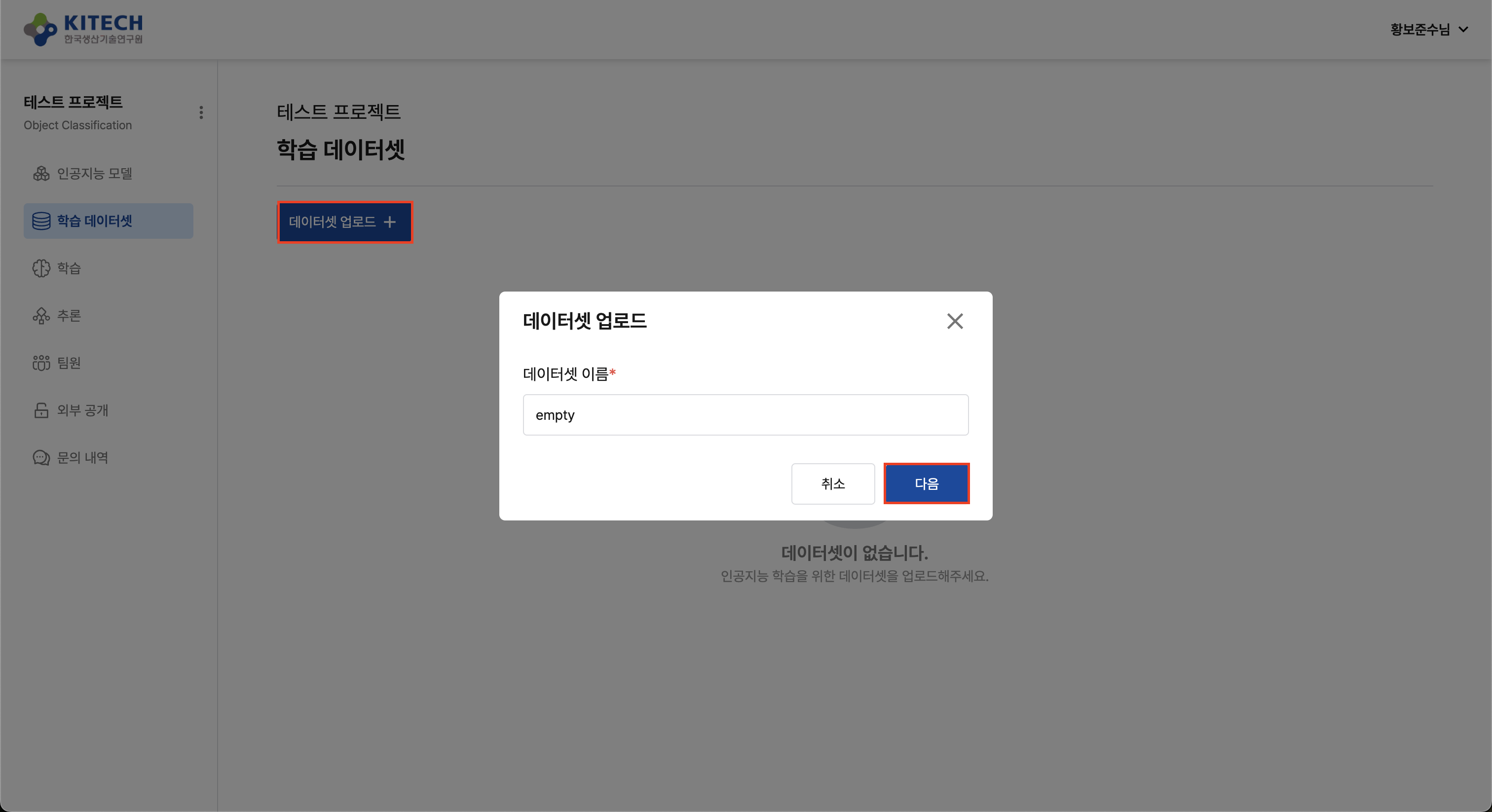
Platform 제약사항으로 학습 실행 시 데이터셋 선택이 필수입니다. Empty Dataset은 실제 파일을 포함하지 않으며, Platform의 데이터셋 선택 요구사항을 충족하기 위한 용도로만 사용됩니다.
자세한 내용: Empty Dataset 개념
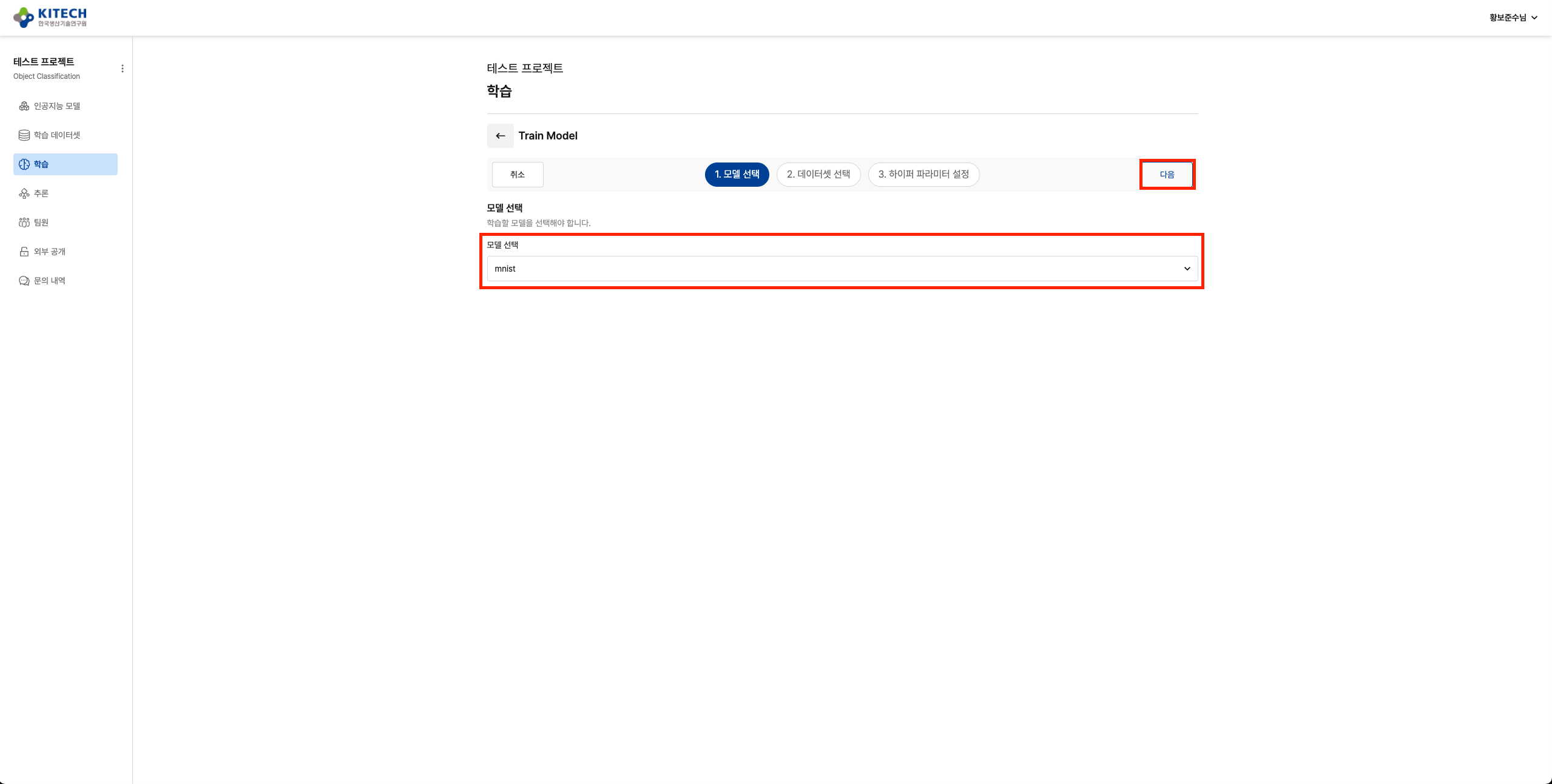
5. 학습 실행
Platform의 "학습" 메뉴로 이동하여 새 학습을 생성합니다.
모델 선택
업로드한 MNIST 학습 모델을 선택합니다.
데이터셋 선택
4번에서 생성한 Empty Dataset을 선택합니다.
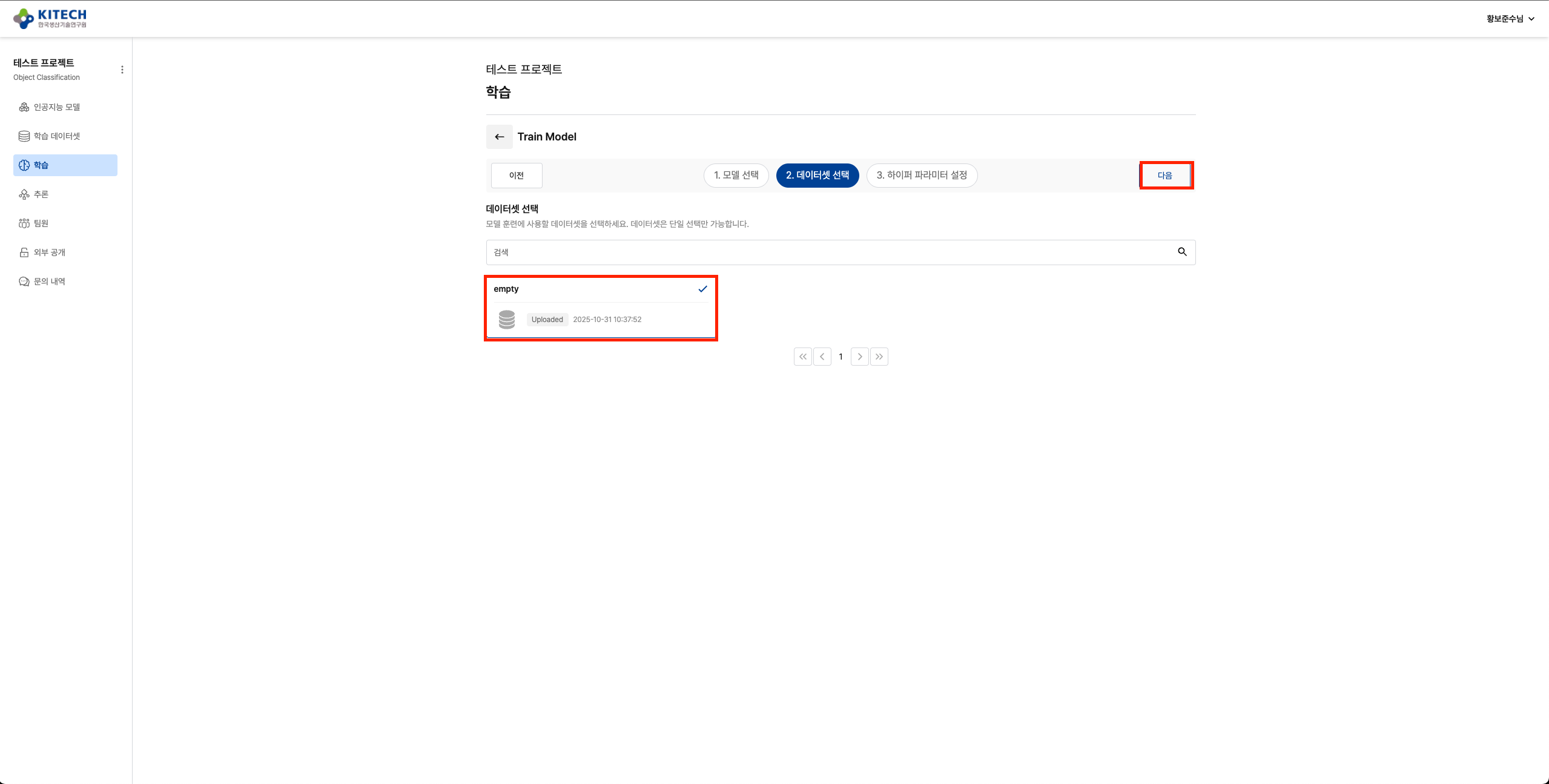
Hyperparameter 설정 (선택사항)
코드에 정의된 기본값(batch-size=64, epochs=5, learning-rate=0.001)으로 학습하거나, 필요한 경우 값을 변경할 수 있습니다.
코드에서 이미 기본값을 정의했으므로, Hyperparameter를 변경하지 않아도 바로 학습이 실행됩니다. Platform에서 Hyperparameter를 미리 등록하는 과정도 필요 없습니다.
사용 가능한 Hyperparameter:
| Parameter | Type | Default | Description |
|---|---|---|---|
| batch-size | int | 64 | Training batch size |
| epochs | int | 5 | Number of training epochs |
| learning-rate | float | 0.001 | Learning rate |
"학습 실행" 버튼을 클릭하면 Platform이 자동으로 다음 작업을 수행합니다:
- 이미지 Pull: Harbor에서 학습 이미지 다운로드 (최초 1회, 10~20분 소요 가능)
- 데이터 준비: data-initializer 컨테이너로 Empty Dataset 마운트 확인
- 학습 실행: train 컨테이너에서 학습 시작
- 런타임에 MNIST 데이터셋 자동 다운로드
- Epoch별 학습 진행
- Validation 수행
- 모델 변환: 학습 완료 후 자동 ONNX 변환
- 결과 업로드: MLflow에 모델 및 메트릭 자동 기록
- 모니터링: monitor 사이드카로 학습 상태 추적
학습 진행 상황 확인
학습이 시작되면 학습 목록에서 상태를 확인할 수 있습니다.
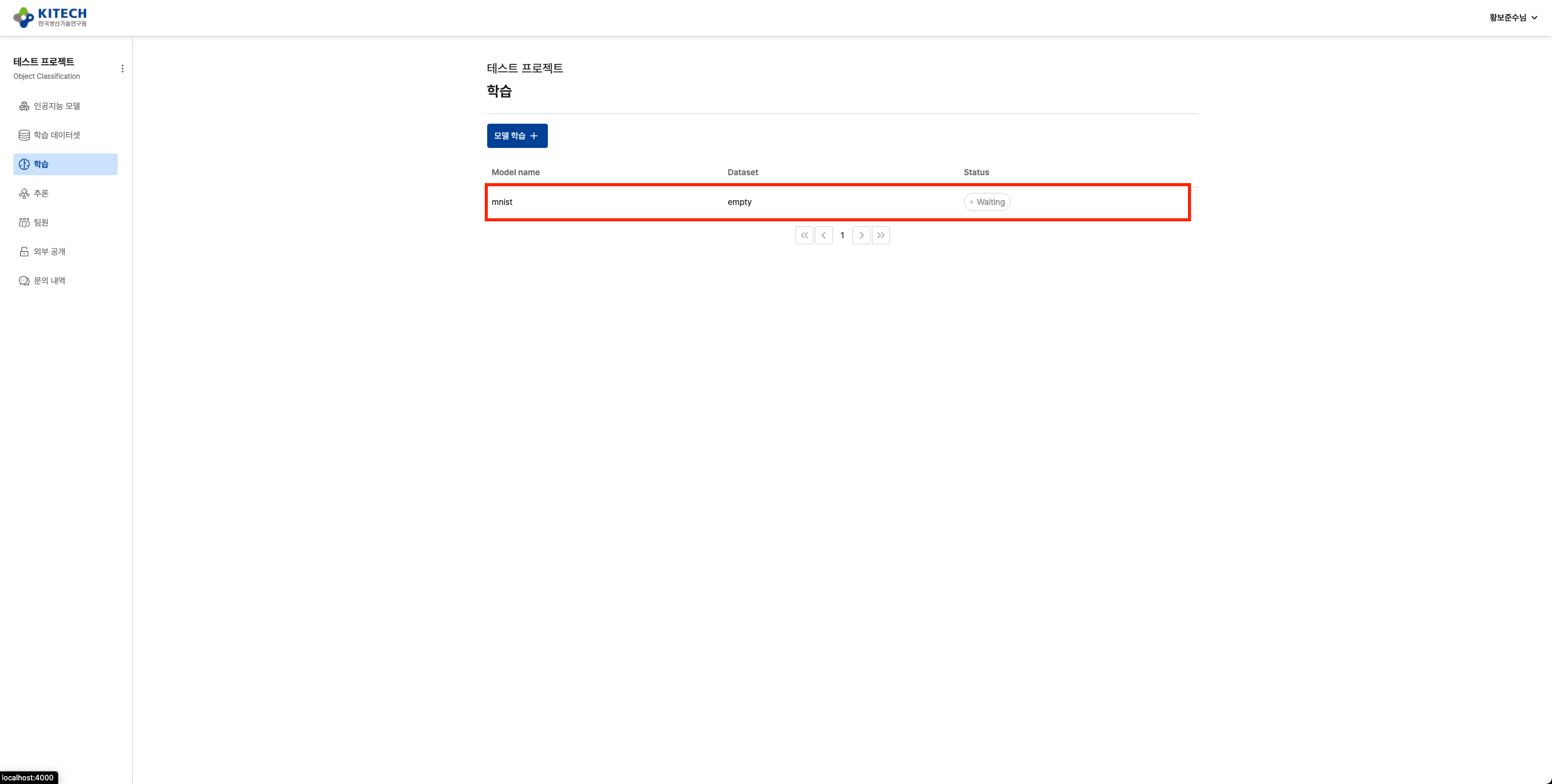
학습을 클릭하여 상세 페이지로 이동하면 학습 정보와 실시간 로그 탭에서 진행 상황을 확인할 수 있습니다.
학습 정보 탭:
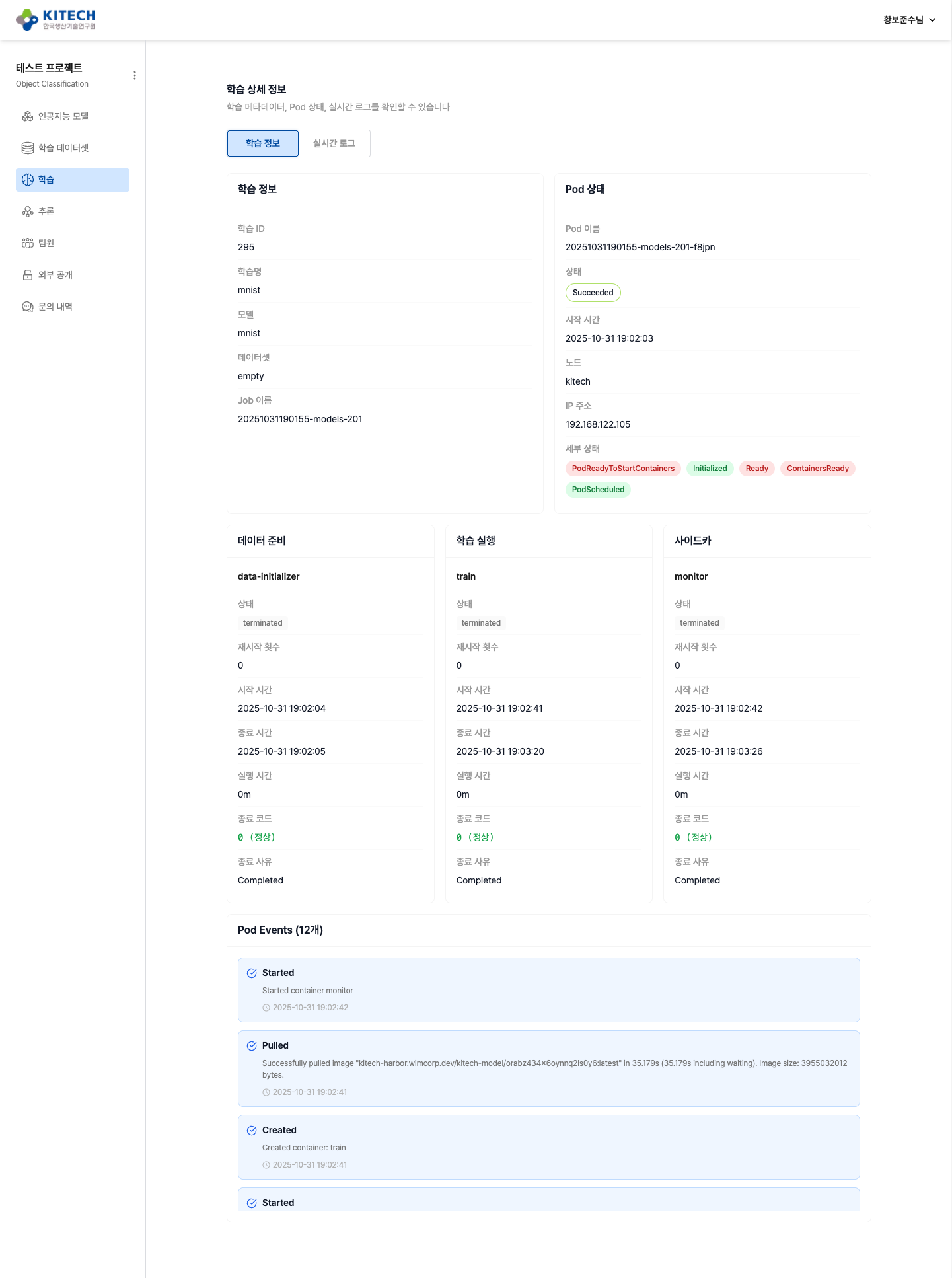
학습 정보 탭에서는 다음 정보를 확인할 수 있습니다:
- 학습 정보: 학습 ID, 학습명, 모델, 데이터셋, Job 이름
- Pod 상태: Pod 이름, 상태(Succeeded/Running/Failed), 시작 시간, 노드, IP 주소, 세부 상태
- 컨테이너 상태:
- 데이터 준비 (data-initializer): Empty Dataset 마운트 확인
- 학습 실행 (train): 실제 학습 프로세스
- 사이드카 (monitor): 학습 모니터링
- Pod Events: Pod 생성부터 종료까지의 이벤트 타임라인
학습 이미지를 pull하는 과정에서 시간이 오래 걸릴 수 있습니다. 학습 이미지 크기가 10GB ~ 20GB 정도 되므로 10분 이상 waiting 상태가 유지될 수 있습니다. 이러한 대기 상태에서의 현황은 Pod Events에서 확인하는 것이 가장 정확합니다.
실시간 로그 탭:
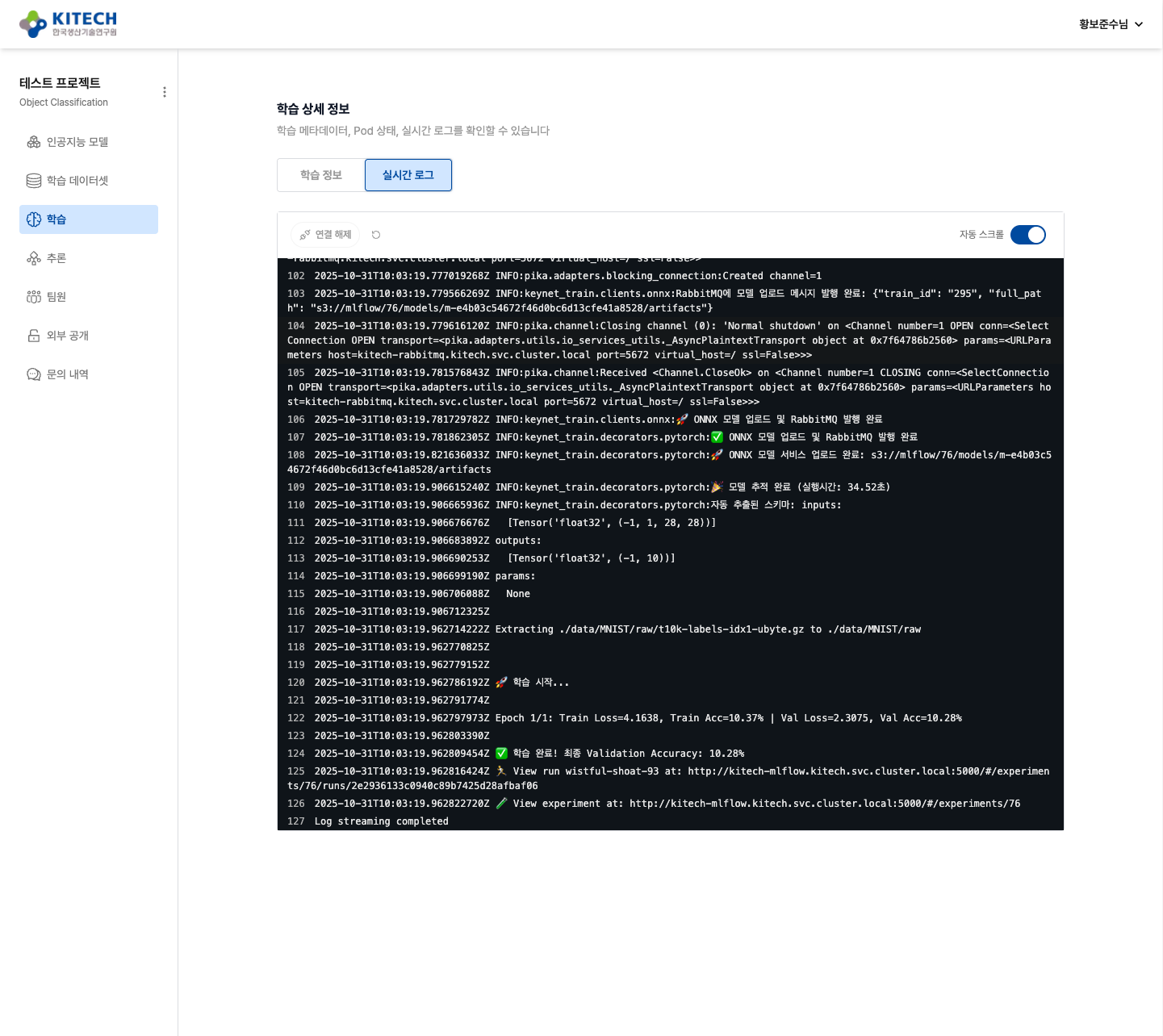
실시간 로그에서는 학습 진행 과정을 실시간으로 확인할 수 있습니다:
- 데이터 다운로드: MNIST 데이터셋 자동 다운로드 진행 상황
- 학습 진행: Epoch별 Train Loss, Train Accuracy, Validation Loss, Validation Accuracy
- ONNX 변환: 학습 완료 후 자동 ONNX 변환
- MLflow 업로드: 모델 및 메타데이터 업로드
예상 로그 출력:
Using device: cuda:0
Downloading MNIST dataset...
🚀 학습 시작...
Epoch 1/5: Train Loss=0.3456, Train Acc=89.23% | Val Loss=0.1234, Val Acc=96.45%
Epoch 2/5: Train Loss=0.1234, Train Acc=96.78% | Val Loss=0.0987, Val Acc=97.12%
...
✅ 학습 완료! 최종 Validation Accuracy: 98.23%
🔄 Converting PyTorch model to ONNX...
✅ ONNX conversion successful: model.onnx
📤 Uploading to MLflow...
Log streaming completed
GPU 인식 실패
증상:
RuntimeError: CUDA error: no kernel image is available for execution on the device
해결:
base_image의 CUDA 버전이 GPU를 지원하지 않습니다. Docker로 첫 학습 실행 가이드를 참고하여 적절한 PyTorch 이미지를 선택하세요.
다음 단계
MNIST 튜토리얼을 완료했습니다! 이제:
- YOLO 객체 탐지 튜토리얼: 실제 데이터셋 업로드 및 coco128.yaml 사용
- Hyperparameter 튜닝: 다양한 설정으로 실험하여 최적의 모델 찾기
- 모델 배포: ONNX 모델을 다운로드하여 프로덕션 환경에 배포