데이터셋
KeyNet Platform에서 학습 모델은 데이터셋을 두 가지 방식으로 사용할 수 있습니다. 각 방식의 특징과 사용 시나리오를 이해하고 적절한 방법을 선택하세요.
데이터셋 사용 방식
1. 학습 이미지에 포함
데이터셋을 학습 코드와 함께 Docker 이미지에 포함하거나, 런타임에 다운로드하는 방식입니다.
방법
Docker 이미지에 포함:
FROM pytorch/pytorch:2.8.0-cuda12.9-cudnn9-runtime
WORKDIR /app
# 데이터셋 복사
COPY dataset/ ./dataset/
COPY train.py .
ENTRYPOINT ["python", "train.py"]
런타임 다운로드:
# MNIST 예시
train_dataset = datasets.MNIST(
"./data",
train=True,
download=True, # 런타임에 자동 다운로드
transform=transform
)
장점
- 별도의 데이터셋 업로드 과정 불필요
- 학습 코드와 데이터가 하나의 이미지로 관리됨
- 소규모 데이터셋에 적합
단점
- 데이터셋을 변경하려면 이미지를 다시 빌드해야 함
- 이미지 크기가 커질 수 있음 (Docker 이미지에 포함 시)
- 여러 모델에서 동일 데이터셋 재사용 어려움
적합한 경우
- 공개 데이터셋 (MNIST, CIFAR-10 등) 사용
- 데이터셋 크기가 작음 (수백 MB 이하)
- 데이터셋이 자주 변경되지 않음
- 빠른 프로토타이핑
2. Platform에 별도 업로드
데이터셋을 Platform에 업로드하여 여러 모델에서 재사용하거나, 동일한 모델로 다른 데이터셋을 교체하며 실험할 수 있습니다.
방법
Platform은 업로드된 데이터셋을 컨테이너 실행 시 /data 경로에 자동으로 마운트합니다:
from keynet_train import DatasetPath
from torchvision import datasets, transforms
# Platform 주입 데이터셋 사용
train_path = DatasetPath("my-dataset", "train") # /data/my-dataset/train
val_path = DatasetPath("my-dataset", "val") # /data/my-dataset/val
# Transform 정의
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
train_dataset = datasets.ImageFolder(train_path, transform=transform)
val_dataset = datasets.ImageFolder(val_path, transform=transform)
장점
- 여러 데이터셋을 쉽게 교체하며 실험 가능
- 데이터셋 버전 관리
- 이미지 크기 절감
- 여러 모델에서 동일 데이터셋 재사용
단점
- 별도의 업로드 과정 필요
- 학습 코드에서 Platform 주입 경로 사용 필요
- 초기 설정이 다소 복잡
적합한 경우
- 커스텀 데이터셋 사용
- 데이터셋 크기가 큼 (수 GB 이상)
- 데이터셋을 자주 변경하며 실험
- 여러 모델에서 동일 데이터셋 재사용
- 프로덕션 환경
Empty Dataset
개념
Empty Dataset은 실제 파일을 포함하지 않는 빈 데이터셋입니다. Platform의 데이터셋 선택 요구사항을 충족하기 위한 용도로만 사용됩니다.
사용 시나리오
런타임에 데이터셋을 다운로드하는 경우 (예: MNIST), Platform에 실제 데이터셋 업로드가 필요 없지만 제약사항으로 인해 데이터셋 선택이 필수입니다.
# MNIST 런타임 다운로드 예시
train_dataset = datasets.MNIST(
"./data",
train=True,
download=True, # 런타임에 다운로드되므로 Platform 업로드 불필요
transform=transform
)
이 경우 Empty Dataset을 생성하여 Platform 요구사항을 충족합니다.
생성 방법
Platform의 "데이터셋 생성" 버튼을 클릭하고, 파일을 업로드하지 않고 저장합니다.
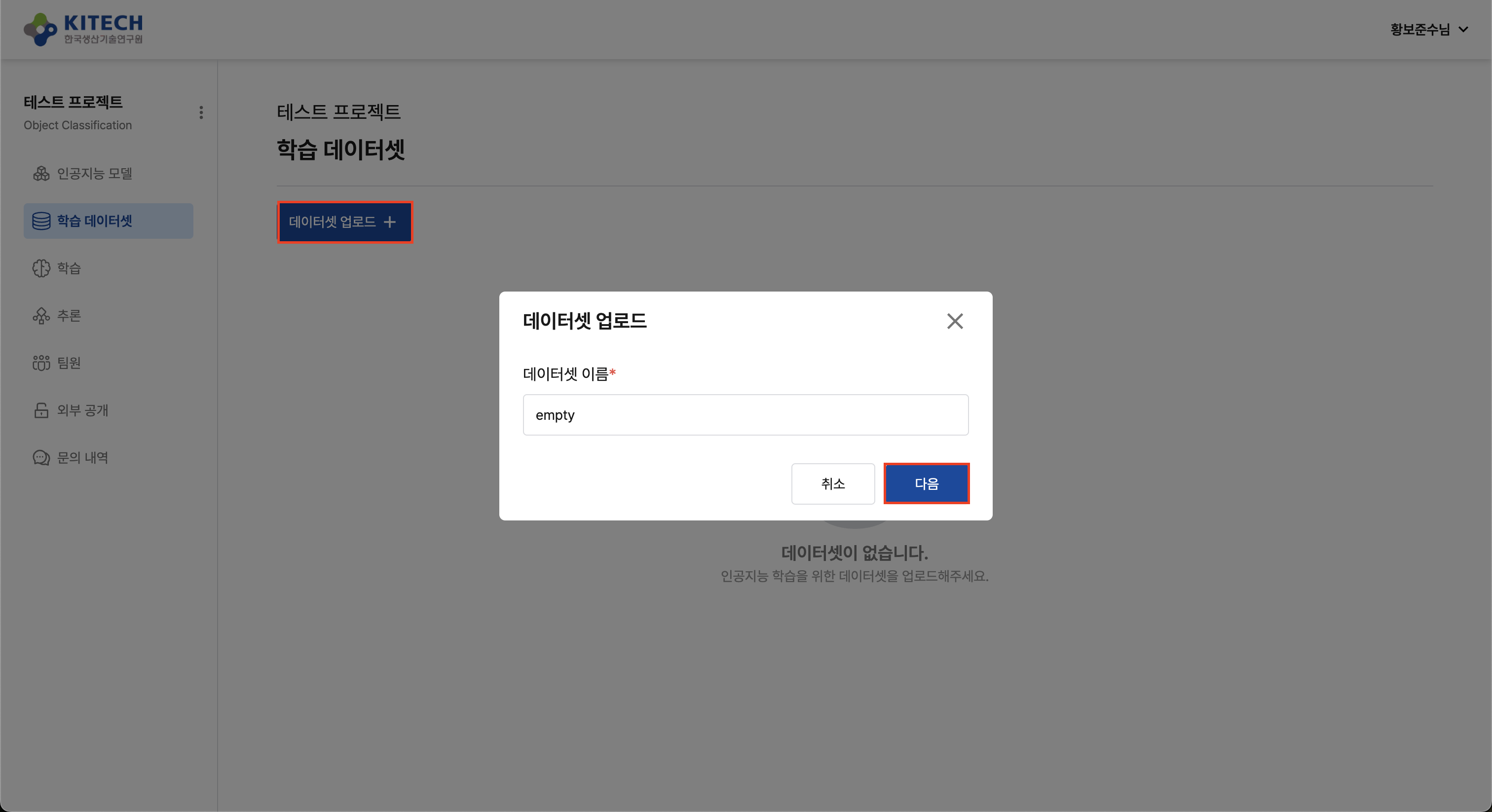
현재 Platform 버전에서는 학습 실행 시 반드시 데이터셋을 선택해야 합니다. 학습 이미지에 데이터셋이 포함되어 있더라도 Empty Dataset을 생성하여 선택해야 합니다.
DatasetPath 유틸리티
Platform에 업로드한 데이터셋을 사용할 때는 keynet-train의 DatasetPath 유틸리티를 사용하여 경로를 안전하게 관리합니다.
기본 사용법
from keynet_train import DatasetPath
# 상대 경로 -> /data/{path}로 자동 변환
path = DatasetPath("coco8", "images", "train")
print(path) # /data/coco8/images/train
# 또는 / 연산자 사용
base = DatasetPath("coco8")
path = base / "images" / "train"
print(path) # /data/coco8/images/train
# 절대 경로는 그대로 사용
absolute = DatasetPath("/absolute/path/to/data")
print(absolute) # /absolute/path/to/data
# 기본 경로만 사용
base_path = DatasetPath()
print(base_path) # /data
환경 변수
기본 경로는 환경 변수로 변경할 수 있습니다:
# 기본값: /data
export DATASET_PATH=/custom/data/path
장점
- Platform 환경과 로컬 환경 모두에서 동작
- 경로 오류 방지
- 상대/절대 경로 자동 처리
- 테스트 시 환경 변수로 경로 변경 가능
방식 비교
| 항목 | 이미지 포함 | Platform 업로드 |
|---|---|---|
| 설정 복잡도 | 낮음 | 중간 |
| 이미지 크기 | 큼 | 작음 |
| 데이터 변경 | 이미지 재빌드 필요 | UI에서 즉시 변경 가능 |
| 재사용성 | 낮음 | 높음 |
| 버전 관리 | 어려움 | 쉬움 |
| 빌드 시간 | 느림 (데이터 포함 시) | 빠름 |
| 적합한 크기 | < 500MB | > 500MB |
| 적합한 단계 | 프로토타이핑 | 프로덕션 |
선택 가이드
다음 플로우차트를 참고하여 적절한 방식을 선택하세요:
실전 예시
MNIST (런타임 다운로드)
# train.py
train_dataset = datasets.MNIST(
"./data",
train=True,
download=True,
transform=transform
)
Platform 설정: Empty Dataset 선택
자세한 내용: MNIST 튜토리얼
YOLO (Platform 업로드)
# train.py
from ultralytics import YOLO
# coco128.yaml을 Docker 이미지에 포함 (/app/coco128.yaml)
# yaml 파일에 Platform 마운트 경로(/data/coco128) 명시
model = YOLO("yolo11n.pt")
model.train(data="./coco128.yaml", ...)
# coco128.yaml (Docker 이미지에 포함)
path: /data/coco128 # Platform이 마운트하는 경로
train: images/train2017
val: images/train2017 # coco128은 train2017만 포함
names:
0: person
# ...
Platform 설정: 업로드한 coco128 데이터셋 선택 (이미지/라벨만)
자세한 내용: YOLO 튜토리얼
다음 단계
데이터셋 개념을 이해했다면:
- 데이터셋 업로드: Platform에 데이터셋 업로드 방법
- MNIST 튜토리얼: 런타임 다운로드 방식 예시
- YOLO 튜토리얼: Platform 업로드 방식 예시